I debated on several different ideas to make as the first one to the blog. After some contemplation I decided to start with the PE File Header*. I've read more than a few and frankly, yawned my way through or just up and left many of them. So, in order to make this different I decided to make it about what I tend to focus on: what can be leveraged as a detection. As a norm, I'll refer to Yara when I talk about detecting things unless I say otherwise. Tends to make it clearer that way. Let's knock out some basics, first.
If you have no idea what structure of a PE File looks like, you need to go
this page and get some fundamentals under your belt first.
Take a second and look into the
Rich Signature that might be present. Our first example will not have this data but the second one will. Look at the differences.
Unfamiliar with Yara? Zip your way to the
Yara docs to find out its uses.
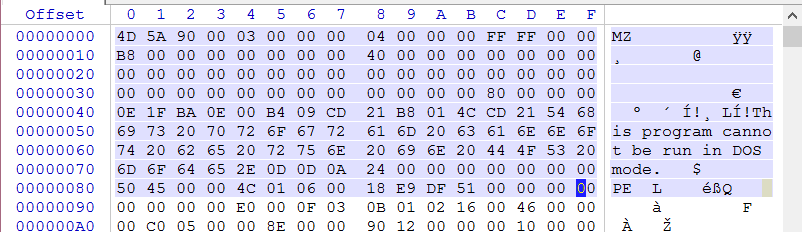
Okay, with those two things out of the way, let's take a look at the beginning of a PE file in a hex editor.
Since we already provided some links to how this structure relates, I'm going to skip some of the blabber you would normally get here. Let's talk about detections for a second. Integral to a lot of yara rules is a check in the condition line to make sure its being compared against the right type of file. The documentation will give an example to make this check like this:
rule IsPE {
condition:
uint16(0) == 0x5A4D and uint32(uint32(0x3C)) == 0x00004550
}
Quite efficient, this checks for the "magic number" of MZ (the 4D 5A value you see in the hex) and for PE (hex 50 45). Most people are much less efficient and just place a string equal to "MZ" before the condition and just check for that at offset 0. Like this:
rule IsPE {
strings:
$mz = "MZ"
condition:
($mz at 0) and (uint32(uint32(0x3C)) == 0x00004550)
}
Frankly, you'll find that just checking for MZ at 0 will work well enough in the condition line. You can even look for "This program cannot be run in DOS mode" if you wanted. Any of the three or singly is usually more than sufficient. A simple means to leverage this with detections is to contrast the magic number, in this case an exe, with its file extension. While simplistic, it acts as a simple means of contrast of contents to purported type. For example, a MZ magic number but a file ending of jpg is an easy give away.
Finding a PE File by its "magic number" or by just looking for MZ at 0 is all well and good when you have an modified file. The hacks and artists that generate malware tend to employ a whole back of tricks to defeat such things. For example, our detection of a valid PE file would fail if we changed the magic numbers to something else, say "XD". Of course, this also means it won't run either since Windows would not identify it as valid anymore. That doesn't invalidate it, though. This tactic happens frequently since a dropper or injector file could easily change those numbers back and execute it. In this instance, you might think of leveraging a rule like this:
rule PEWrongMagicNumber {
strings:
$mz = "MZ"
$msdos = "This program cannot be run in DOS mode"
condition:
($mz at 0) or $msdos or (uint32(uint32(0x3C)) == 0x00004550)
}
Saying that nothing else had been done beyond that, the above rule would still flag that it was a PE File. Of course, it would be just one in a series of matches you would want to do before flagging it in any specific fashion. A lot of permutations exist here. Let's focus on a couple. The previous rule checks for the existence of one of the three items common to all PE Files. What about if one of them was missing? The below rules looks at three possibilities where one but not the second or third exists.
rule MissingEssential{
strings:
$mz = "MZ"
$msdos = "This program cannot be run in DOS mode"
condition:
(($mz at 0) and not ($msdos or (uint32(uint32(0x3C)) == 0x00004550))) or
(($msdos and not (uint32(uint32(0x3C)) == 0x00004550) or ($mz at 0))) or
((uint32(uint32(0x3C)) == 0x00004550) and not (($mz at 0) or $msdos))
}
Before I move into a second example, I'd like to point out that you should confine the signatures above to just the first 300 of a file. For example, adding "in 0..300". You can make this smaller and in most cases its no issue to use just "0..100" as well.
Let's look at the beginning of a different PE File. This one has the Rich Signature data.
Here, you'll see the Rich data between the "This program cannot be run in DOS mode." and "PE".
If you read the link provided earlier, you'll realize this means the PE File was created by a Microsoft Compiler. That can be handy, especially if you have some intel that indicates your focus might be with a Microsoft crafted PE File over, say, a Delphi one.
rule IsMicrosoftPE {
strings:
$mz = "MZ"
$rich = "Rich"
condition:
($mz at 0) and ($rich in (0..300)) and (uint32(uint32(0x3C)) == 0x00004550)
}
Having the product version of the Microsoft compiler might be useful, so this might be an interesting detection to look for and then extract the data to use as an indicator to find or type malware families or builders with. Additionally, since the linker data in the Rich signature points to linker database, you can pivot from the data and find the list of linked libraries. Also another good indicator for typing and grouping malware.
Before I end the introduction to this part of the PE File Header, let's tackle one more item. We know a couple of things about this piece of the File Header. First, we have a couple of known values. "MZ", "This program cannot be run in DOS mode" and "PE". You could could count the "Rich" value as well if desired. This gives us some typically unchanging data points to work with, especially when you are presented with something where a PE File is obfuscated, saying with XOR. To use this information properly, you need to also know that the magic number (4D 5A) is followed by a 90 00 03 00 and that XOR has a flaw. That flaw is that any byte you XOR with 0 stays the same. Given that a PE File should start with 4D 5A 90 00 03 00, if you XOR'd the file with a value, every "0" takes on the value of the XOR key. That becomes something we can detect with our handy Yara tool. Let's take a
simple example of an XOR by 0x33 (the number "3").
*** run this only after you have previously identified the file as a possible PE File
rule PEIsXOR {
strings:
$xormz = { 4D 69 90 33 03 33 }
$mz = { 4D 5A 90 00 03 00 }
condition:
($xormz in (0..10)) and not ($mz in (0..10))
}
To make this work effectively you would need a larger yara rule that matches against the full ascii table for a single byte XOR. Of course, more complex ones would easily defeat this kind of check. The downside to complexity is simplicity tends to fall by the side. For example, a common PE File will have numerous "00" ascii values.
rule PENoZeros {
strings:
$zero = { 00 }
condition:
$zero in (0..100)
}
Again, not something to run singly since it will be slow, even if only looking the first 100. It should be bound to other rules to provide good context, like checking for normal PE, Wrong Magic Number, Missing Essential, etc.
As a parting thought, remember my point about the known values? You can leverage this information with a little work, even against more complex keys. We'll cover this in more detail in future detail.
* I'm quite aware that the region I'm referencing is more accurately called the MS DOS header and the "This program cannot be run in DOS mode" is properly the MS-DOS stub. I've always called the whole thing the PE Header and didn't see any reason to stop now.